I media stanno parlando diffusamente dell’impatto del Regolamento europeo in materia di protezione dei dati personali (GDPR) dell’Unione eruopea in diversi settori, ma poco hanno detto a proposito di come le nuove norme interesseranno anche la stessa industria mediatica. La causa di ciò potrebbe essere il fatto che gli editori si dichiarino molto informati in questo senso: secondo i dati del Reuters Institute for the Study of Journalism, infatti, il 64% di essi si sente preparato per l’entrata in vigore del GDPR. Una percentuale sbalorditiva, se si considera che nella maggior parte degli altri settori solo una quota fra il 15 e il 30% si è detta preparata in modo adeguato.
Si dovrebbe, però, considerare un altro fattore per giustificare questa presunta sicurezza: la percezione (errata) che niente nel modo in cui le organizzazioni mediatiche raccolgono e usano i dati dei loro lettori sia peculiare, e che esse non rientrino nel modello di applicazione del GDPR. Questo sarebbe un grosso errore, perché la maggior parte delle organizzazioni mediatiche ha gli attributi distintivi per essere collocata esattamente nel raggio d’azione del GDPR e di conseguenza le imprese coinvolte saranno costrette ad attenersi anche ai requisiti più stringenti della nuova normativa. Per chi avesse trascorso gli ultimi mesi dentro una caverna, il GDPR è la nuova legge sulla protezione dei dati dell’Unione europea che aumenta il raggio d’azione, il numero e la profondità dei diritti che le imprese devono garantire ai loro clienti europei e comporta provvedimenti più severe per gli inadempienti. Il GDPR entrerà in vigore il prossimo 25 maggio.
Un disclaimer sull’utilizzo dei dati sul sito della Bbc
Casi di utilizzo dei dati personali in una “tipica” organizzazione mediatica
Per capire come il GDPR influenzerà il lavoro delle organizzazioni mediatiche, passiamo in rassegna alcuni assunti su come un “tipico” editore potrebbe lavorare da una prospettiva dei dati personali. La maggior parte se non tutti gli editori operano sulla base di due modelli di business principali: abbonamenti e/o pubblicità mirata. Entrambi i modelli prevedono la gestione dei dati come una delle funzionalità principali ed entrambi processano regolarmente informazioni personali dei lettori/utenti, tipicamente attraverso processi automatizzati che inviano email di marketing o decidono quali inserzioni saranno mostrate al pubblico. Anche a uno sguardo superficiale queste considerazioni rendono quanto meno probabile che gli editori avranno bisogno di alcune figure esperte di GDPR e provvedimenti tecnici – come un responsabile della protezione dati e un registro degli utilizzi dei dati degli utenti – al fine di rispettare le nuove norme.
A differenza di altri settori in cui le aziende più piccole sono esentate da queste richieste, anche le organizzazioni mediatiche più ristrette corrono il rischio di dover rispondere ai nuovi requisiti. Ciò è dovuto all’elevata saturazione regionale dei dati personali raccolti dai media, una caratteristiche che ipoteticamente consentirebbe loro (o a un data broker) di creare profili dettagliati di ridotte demografiche localizzate su un territorio specifico. La Commissione europea sembra condividere questa preoccupazione, visto che la sua definizione di elaborazione “su larga scala” dei dati riguarda sia il volume assoluto di dati personali analizzati e raccolti, che la proporzione su una specifica popolazione. E se nell’utilizzo “su larga scala” rientra anche la regolare elaborazione automatizzata dei dati personali, allora anche le organizzazioni più piccole e locali probabilmente dovranno essere preparate nei minimi dettagli per soddisfare i requisiti del GDPR.
Raccogliere, profilare, personalizzare.
Operativamente, le piattaforme di news online cominciano tutte dalle stesse procedure generali indipendentemente dal proprio modello di business. Quando clicco su sito di informazione, ad esempio, questo individua il mio indirizzo IP e crea un unique session ID che mi segue e mi rende riconoscibile mentre utilizzo il sito. Anche prima che io raggiunga una specifica data, questo traccia la mia posizione, contenuta nell’indirizzo IP, e mi guida a una versione della homepage personalizzata per la regione in cui mi trovo. Invece, mentre navigo tra i contenuti, fornisco all’organizzazione informazioni sui miei interessi, che possono essere usate per raccomandare articoli o prodotti correlati, o pubblicità coerenti con le mie caratteristiche.
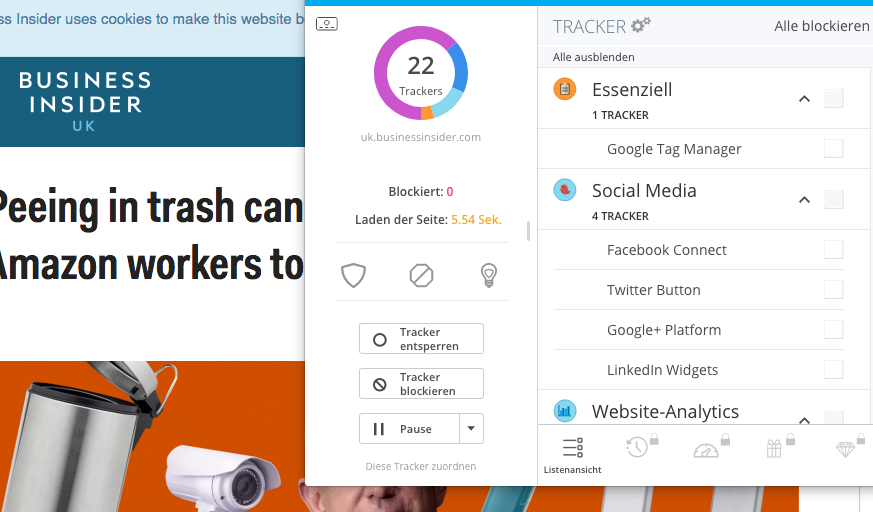
Chi traccia i lettori di Business Insider? (Screenshot a cura dell’autore)
È a questo punto, però, che il modello di business di un’organizzazione diventa importante per determinare quali elementi del GDPR siano interessati. Se i miei guadagni provengono dalla pubblicità mirata, ad esempio, le nuove norme mi costringeranno a fornire agli utenti la possibilità di disattivare tutti i cookies non necessari alla funzionalità del sito (per esempio i più interessanti dal punto di vista dei profitti, come quelli di Google Analytics, DoubleClick, o Adsense). Se opero con un modello basato sugli abbonamenti, invece, allora è probabile che raccolga nel complesso più tipi di dati personali e che questi siano anche più sensibili. Il Times e Der Spiegel, ad esempio, richiedono esplicitamente dati di “categoria speciale” come il genere per registrare un account sui loro siti. Bbc, invece, non lo fa.
Se un’organizzazione di news decidesse di combinare i processi automatizzati (come quelli per creare newsletter o homepage personalizzate) con i dati di categoria speciale (per esempio utilizzando apparentemente innocua metrica “Titolo” come proxy per estrapolare il genere nei suoi algoritmi), allora il GDPR entrerebbe di nuovo in azione. Invece di consentire sei “ambiti legittimi per l’elaborazione”, l’Articolo 22(4) del nuovo GDPR incanala infatti le organizzazioni di news in un solo criterio, quello del “consenso esplicito”. Il consenso esplicito non solo è molto più difficile da ottenere sotto il GDPR, ma richiede anche che le aziende forniscano alcuni dei diritti più complessi da un punto di vista dell’implementazione, come la cancellazione.
Verso un migliore standard di trasparenza
Guardando al futuro sulla base delle tendenze del settore, gli editori ricadranno ancora più spesso nell’ambito d’azione delle norme del GDPR. Dato che gli editori cercano di rompere la propria dipendenza dai modelli di business basati sulla pubblicità e le piattaforme social, essi andranno sempre di più nella direzione della personalizzazione e della profilazione per attrarre e trattenere gli utenti sui propri siti. Ciò vuol dire che dovranno essere molto più trasparenti sul tipo di dati che raccolgono e sul perché. Questo significherà anche che dovranno spiegare i meccanismi, attualmente oscuri funzionamenti degli algoritmi che usano per personalizzare le homepage, profilare gli utenti e svolgere altre attività.
Inoltre dovranno anche concentrarsi sull’implementare i mezzi tecnici per garantire diritti come la cancellazione dei dati degli utenti e la disattivazione dei cookies e determinare se abbiano bisogno o meno di un responsabile della protezione dei dati e un registro delle loro attività di elaborazione. Se tutto questo è già stato preso in considerazione da qule 64% dell’industria dell’informazione europea, allora tanto di cappello. Ma in caso contrario (e comunque per il restante 36%), raccomanderei di mettersi a lavoro perché c’è ancora molto da fare.
Articolo tradotto dall’originale inglese da Giulia Quarta. L’autore è un dipendente di Sovy, una startup tecnologica che si occupa di compliance tecnologica. Le opinioni qui espresse sono da considerarsi esclusivamente dell’autore e non rappresentano necessariamente quelle dell’Ejo o di Sovy.

Tags:dati personali, garante della Privacy, GDPR, Privacy, regolamentazione, Unione europe















