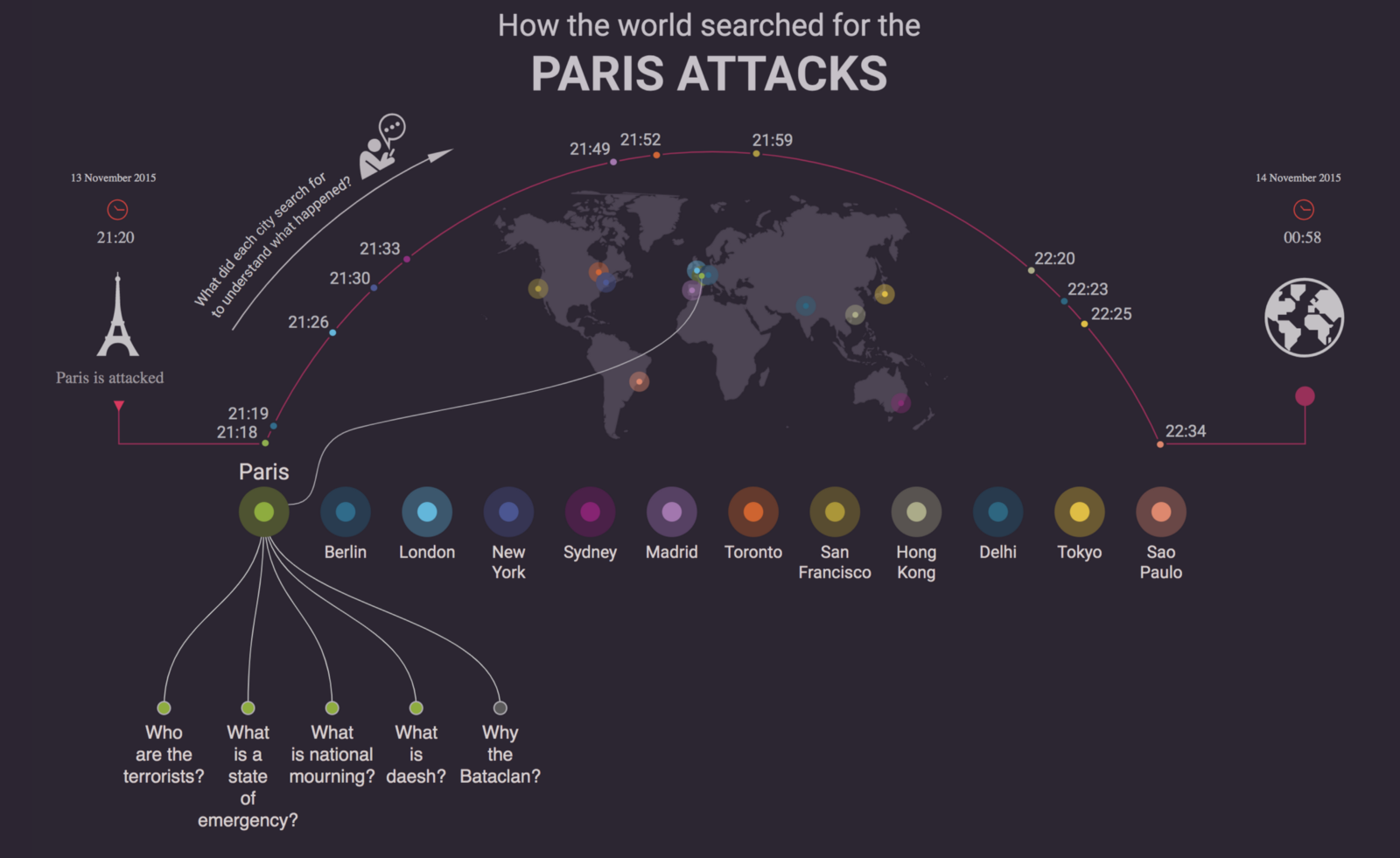
How the world searched for the Paris attacks / Google Trends
Questo articolo è apparso originariamente sul profilo Medium dell’European Journalism Centre. Viene ripubblicato per gentile concessione dell’autrice. Traduzione a cura di Claudia Aletti.
In dieci anni il data journalism è passato da attività di nicchia a essere una componente fondamentale del lavoro delle redazioni di tutto il mondo. Per capire come il data journalism è cambiato in questi ultimi 10 anni abbiamo parlato con Simon Rogers, il fondatore del Guardian Datablog che ha iniziato a pubblicare i suoi primi dati raccolti nel 2009. Quel che state per leggere è ciò che Rogers ci ha raccontato del suo percorso professionale da Londra alla Silicon Valley, dove attualmente è data editor per conto del Google News Lab.
Come ti sei avvicinato al data journalism?
“Quando ho deciso di voler diventare giornalista, tra la prima e la seconda elementare, non ho mai pensato che ciò avrebbe implicato avere a che fare con i dati. Adesso che lavoro con i dati tutti i giorni capisco quanto io sia stato fortunato. Certo non è stato il frutto di una carriera pianificata accuratamente. Mi sono semplicemente trovato al posto giusto nel momento giusto. Il modo in cui questo è accaduto dice molto a proposito dello stato del data journalism nel 2009, e credo ci dica molto anche del data journalism nel 2019. Adrian Holovaty, uno sviluppatore di Chicago che lavorava per il Washington Post e che ha avviato Everyblock, era venuto a parlare nella redazione del Guardian, a Farrington Road, Londra. A quei tempi lavoravo come redattore per l’edizione cartacea, allora ancora preponderante, collaborando alla versione online e curando una sezione scientifica. Più Holovaty parlava di sfruttare i dati, sia per scrivere storie che per aiutare le persone a comprendere il mondo, più l’idea mi solleticava. Non solo si poteva fare, ma in effetti era quello che io stavo già facendo sempre più di frequente. Forse, pensavo, potevo essere davvero un giornalista che lavorava con i dati, un data journalist”.
Qual è stato il suo primo progetto di data journalism?
“Lavorando con i grafici in qualità di news editor, ho accumulato un mucchio di numeri: Matt McAllister, che stava lavorando alle Api aperte del Guardian, le riteneva una miniera d’oro. Avevamo dati sul pil, sulle emissioni di carbonio, sulle spese del governo e molto altro ancora, il tutto salvato come tabulato elettronico di Google e pronto all’uso appena ne avessimo avuto bisogno. E se questi dati fossero pubblicati sotto forma di open data, ci chiedevamo? Niente pdf, solo dati interessanti pronti per essere usati da chiunque. È quello che abbiamo fatto con il Datablog del Guardian – inizialmente con 200 diversi dataset: percentuali di criminalità, indicatori economici, informazioni sulle zone di guerra e persino sulla fashion week e i cattivi di Doctor Who. Abbiamo iniziato a capire che i dati si possono applicare ad ogni cosa. Si trattava ancora di un’attività un po’ strana allora. Quello di data editor era un lavoro rarissimo – e proprio poche redazioni avevano un qualche genere di team dedicato ai dati. In realtà anche solo impiegare la parola ‘dati’ in una riunione avrebbe suscitato delle risatine. Non si trattava di ‘vero giornalismo’, giusto?”
E quando le cose hanno iniziato a cambiare?
“Il 2009 è stato l’anno in cui ha avuto inizio la rivoluzione degli open data: il data hub data.gov del governo degli Stati Uniti è stato lanciato nel maggio di quell’anno con soli 47 dataset. I portali di open data sono stati poi aperti dai Paesi e dalle città di tutto il mondo e gli attivisti chiedevano accesso a sempre più informazioni. In un anno, i nostri lettori ci hanno aiutato a mettere insieme migliaia di note spese dei membri del parlamento e il governo britannico ha rilasciato gli ultimi dati a riguardo: il Combined Online Information System e il team del Guardian hanno messo a punto un portale d’esplorazione interattivo per incoraggiare i lettori a scoprire entrambi. Un anno dopo, il team investigativo del Guardian era alle prese con un massiccio rilascio di documenti dell’esercito statunitense riguardanti l’Iraq e l’Afghanistan (i file consegnati a WikiLeaks da Chelsea Manning, ndr) e il data journalism era un campo ormai ben collaudato. Verso la fine del 2011, l’anno precedente alla prima pubblicazione del Data Journalism Handbook, il progetto ‘Reading the Riots’ ha invece applicato le tecniche di reportage computerizzato sviluppate da Phil Mayer negli anni ’60 a l’inchiesta su un’escalation di violenza in tutta l’Inghilterra”.
Cosa dicono questi progetti sull’evoluzione del data journalism?
“Il punto non è quello di elencare i progetti, ma di mettere in luce quel che è avvento in quei pochi anni, non solo al Guardian, ma nelle redazioni di tutto il mondo. Il New York Times, il LA Times, la Nación in Argentina: ovunque i giornalisti stavano scoprendo un nuovo modo di lavorare, scrivendo articoli supportati dai dati in modo innovativo. È questo il background della prima edizione del Data Journalism Handbook. Il data journalism è passato dall’essere il territorio di pochi solitari all’essere una parte imprescindibile di ogni redazione. Ma già allora una tendenza era ben chiara: se fosse nata una nuova tecnica di scrittura, non solo i dati sarebbero stati una parte fondamentale, ma i data journalist avrebbero occupato un ruolo centrale. In meno di tre anni, i giornalisti hanno raccolto dati, li hanno pubblicati, il crowdsoucing è divenuto uno strumento giornalistico riconosciuto e sono stati impiegati database per occuparsi di grandi quantità di documenti ammassati e sono state applicate a notizie complesse le tecniche di scienze sociali fondate sui dati. Questo non deve essere visto come un progresso isolato nel campo del giornalismo. Si tratta semplicemente degli effetti degli enormi sviluppi nella trasparenza internazionale al di là della creazione di portali di dati aperti”.
Potresti citare alcuni di questi sviluppi?
“Le campagne come quelle condotte dall’Open Knowledge Fundation per accrescere le pressioni sul governo britannico al fine di rendere disponibili ulteriori dati all’utilizzo pubblico e fornire delle Api che chiunque possa usare. Ma anche un maggiore accesso a strumenti gratuiti per la visualizzazione e la pulizia dei dati, come Open Refine, Google Fusion Tables, Many Eyes (di Ibm), Datawrapper, Tableau Public e altri ancora. Questi strumenti gratuiti, insieme all’accesso a una gran quantità di dati pubblici, hanno facilitato la produzione di modalità di visualizzazione e analisi dei dati sempre più orientate al pubblico. Redazioni come quelle del Texas Tribune e di ProPublica hanno cominciato a sviluppare dei progetti a partire da questi dati. Vedete come funziona? Un circolo virtuoso di dati, semplice elaborazione, visualizzazione, ancora più dati e così via. Più dati sono disponibili, più lavoro viene fatto grazie ad essi e maggiore è la pressione per il rilascio di ulteriori informazioni. Scrivendo l’articolo ‘Data Journalism is the New Punk’ (ne abbiamo parlato qui, ndr) volevo dimostrare una cosa: eravamo a un punto in cui la creatività poteva realmente correre libera, ma anche in cui questo lavoro alla fine sarebbe diventato comune”.
Che significa diventare “convenzionale” per il data journalism?
“Quando ho avuto l’opportunità di trasferirmi in California e di diventare il primo data editor di Twitter, era chiaro che i dati fossero entrati a far parte del vocabolario comune dell’editoria. Un bel numero di progetti giornalistici, come Upshot del New York Times e FiveThirtyEight di Nate Silver, sono nati a poche settimane di distanza l’uno dall’altro. Il pubblico là fuori nel mondo stava diventando sempre più alfabetizzato visivamente e riusciva a comprendere le modalità di visualizzazione di dati relativi a tematiche complesse molto più facilmente di prima. Vi chiederete quali prove ho che il mondo si trovi a proprio agio con la visualizzazione di dati? Non molte, oltre la mia esperienza del fatto che realizzare un’immagine che susciti una grande reazione online è più difficile ora di quanto non fosse in passato. Se tutti rispondevamo con degli ‘ooh’ e degli ‘ah’ alle infografiche, adesso è più difficile ottenere qualcosa che vada oltre un’alzata di spalle”.

Simon Rogers
“Quando sono entrato a far parte del Google News Lab per lavorare sul data journalism era ormai evidente che quel campo avesse accesso a una quantità di dati nettamente più grande e vasta rispetto a prima. Ogni giorno, per esempio, vengono fatte milioni di ricerche di cui una parte significativa non è mai stata fatta prima. Inoltre, sempre più reporter prendono questi dati e li analizzano insieme ai tweet e ai like di Facebook. Come pratica, il data journalism è anche più diffusa di quanto non sia mai stata. Nel 2016, i Data Journalism Awards hanno ricevuto un record di 471 candidature. Ma l’edizione 2018 ne ha ricevute quasi 700, di cui oltre la metà proveniva da piccole redazioni e molte venivano da tutto il mondo. L’intelligenza artificiale, o apprendimento automatico, è diventata una risorsa per il data journalism, come dimostra il recente articolo su BuzzFeed di Peter Aldhous. Nel frattempo, la disponibilità di nuove tecnologie come la realtà virtuale e aumentata può permettere ai designer di illustrare i dati presenti nelle notizie in modi più interessanti, rendendo una storia più realistica e coinvolgente per il pubblico. Ora il mio compito è quello di immaginare come il data journalism potrebbe evolversi – e cosa si potrebbe fare per sostenerlo. Ciò significa che ora, oltre a lavorare alla stesura di storie a partire da dati, stiamo creando progetti che rendano più facile l’impiego di queste nuove tecnologie. Per esempio, abbiamo lavorato di recente con lo studio di design Datavized per realizzare TwoTone, uno supporto visivo che trasforma i dati in suoni”.
Quali sfide prevedi per il futuro?
“Le sfide sono grandi. Le informazioni vengono consumate in modi sempre più dinamici, il che comporta certe difficoltà. I giorni in cui i dati venivano visualizzati in complesse modalità a schermo intero si sono scontrati con il fatto che più della metà delle persone ora legge le notizie dallo smartphone o da altri dispositivi mobili (un terzo lo fa seduto sulla toilette, stando al Reuters News Consumption Study del 2017). Ciò significa che sempre più spesso i designer che lavorano per una testata giornalistica devono fare i conti con schermi minuscoli e un’attenzione sempre minore. C’è anche un nuovo problema che può impedirci di imparare dal passato. Il codice non c’è più, le biblioteche marciscono e alla fine gran parte del lavoro più ambizioso del giornalismo semplicemente non esiste più. ‘MPs Expenses’, ‘Everyblock’ e altri progetti hanno tutti ceduto davanti ad una memoria istituzionale che sta scomparendo. Ci troviamo di fronte a una questione più ampia e sempre più allarmante: quella della fiducia. L’analisi dei dati è sempre stata soggetta a interpretazioni e divergenze, ma un buon data journalist può superare questo problema. In un momento in cui la fiducia nelle notizie e una serie di fatti condivisi vengono messi ogni giorno in dubbio, il data journalism può illuminarci la strada portando alla luce fatti e prove in un modo accessibile. Nonostante tutti i cambiamenti, alcune cose restano costanti in questo ambito. Il data journalism ha una storia lunga, ma nel 2009 è parso come un modo per giungere a una verità comune, un qualcosa che tutti potrebbero accettare. E ora questo bisogno è più grande che mai”.
Recentemente l’European Journalism Centre ha lanciato una nuova piattaforma per gli appassionati di data journalism: DataJournalism.com. Come credi si possa inserire nel panorama del data journalism nel 2019?
“È molto facile per i data journalist sentirsi isolati in quello che fanno ogni giorno. Spesso lavorano per conto loro, cercando di affrontare questioni complesse che nessun altro in redazione capisce. Questo sito aiuterà non solo coloro che hanno appena iniziato, ma anche tutti gli altri, dal singolo professionista al membro di un grande team, a sentire un po’ di supporto. Un semplice sito dove vedere cosa è stato fatto in precedenza, e in che modo e quando sarebbe il caso di emularlo, farà un’enorme differenza. È facile dimenticarsi di non essere i primi a provare una certa cosa, ma che c’è un’intera rete di contatti che aspetta solo di aiutare. È questo quello che fa questo sito – ci dà una casa”.












